
Nomic Embed is at the forefront of embedding models, offering a high-performance, efficient alternative to larger embedding models.
Nomic Embed placed in the top-5 on MTEB Arena, a dynamic leaderboard that evaluates embedding models through head-to-head comparisons. Nomic Embed is 3-70x times smaller than other models in the top-10, showcasing its real-world performance and efficiency.
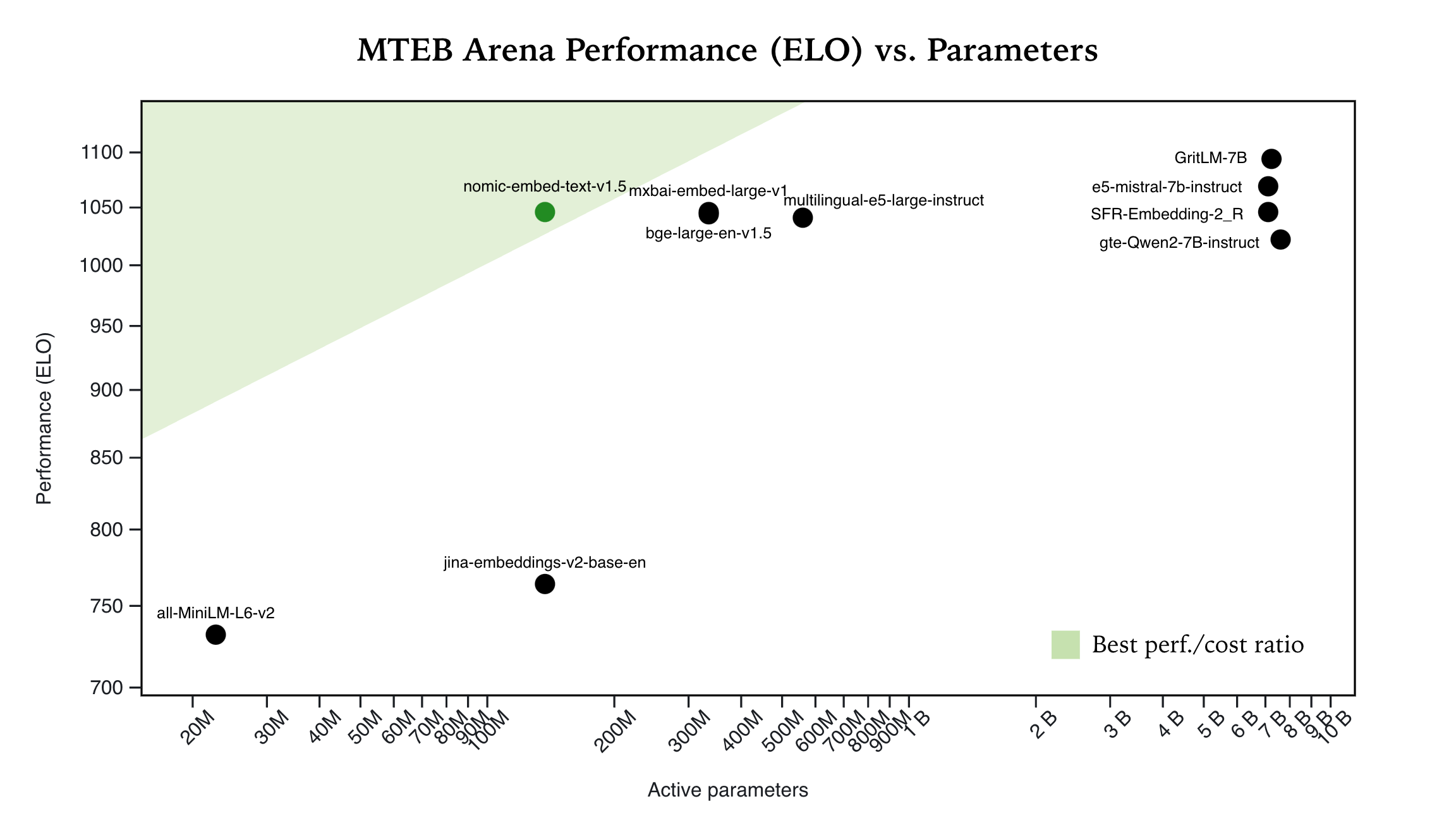
Nomic Embed is at the Pareto frontier of embedding models, offering an optimal trade-off between efficiency and effectiveness. Users can benefit from high-quality embeddings with low computational costs.
This challenges the current trend in embedding models of taking a "bigger is better" approach and finetuning Large Language Models.
Traditionally, embedding models have been ranked using static benchmarks like MTEB (Massive Text Embedding Benchmark). While these scores provide valuable insights, they don't tell the whole story.
Static benchmarks can be overfit, where models are optimized for specific test sets rather than real-world performance. Many models today have been trained on the training sets of the benchmarks and/or trained on synthetic data that is similar to the benchmark data.
MTEB Arena was recently released as a new blind evaluation platform that addresses these limitations. MTEB Arena pits embedding models against each other in direct, head-to-head comparisons. Here's how it works:
This approach offers several advantages:
Nomic Embed can be used through Huggingface and Nomic's Embedding API.
You can access the API via HTTP and your Nomic API Key:
curl https://api-atlas.nomic.ai/v1/embedding/text \
-H "Authorization: Bearer $NOMIC_API_KEY" \
-H "Content-Type: application/json" \
-d '{ "model": "nomic-embed-text-v1",
"texts": ["Nomic AI introduces Nomic Embed", "#keepAIOpen"]}'
and in the official Nomic Python Client after you pip install nomic,
from nomic import embed
import numpy as np
output = embed.text(
texts=[
"Who is Laurens van der Maaten?",
"What is dimensionality reduction?",
],
model='nomic-embed-text-v1',
)
print(output['usage'])
embeddings = np.array(output['embeddings'])
print(embeddings.shape)
